|
keyword: ウェブ小説, 統計, データ分析, 更新停止, エターナる, 小説家になろう
概要
小説家になろう」において連載小説が未完のまま永久更新停止(エターナる)に陥る理由
を明らかにすべく、データを集めシンプルな分析をした。この記事では、問題の背景について述べたあと、
データの概要と手法を説明する。その後予測のパフォーマンスを示し、分析結果を考察している。
結果にのみ興味のある読者はページ下の結論を読んで欲しい。
データは利用可能。
背景
ネット小説の1つの特徴として、未完のまま永久に更新が停止すること(エターナる)が非常に多い。少なくとも商業出
版の小説と比較するとその傾向は圧倒的とされ、一説では9割以上とも
言われる。
ネット小説を読む側にとって、エターは深刻な問題である。読者の側からは(ひょっとすると作者にとっても)
その小説が今後更新されるか予測がつかず、更新されたかどうかを何年も気にしてサイトにアクセスし続けることになる。
(そして多くの場合、更新がないことにを確認し、その都度がっかりする。)
このような悲劇の存在が読者側の作品発
掘意欲を削ぎ(それによって作者が応答を受け取る機会を減らすという形で)、結果としてネット小説界隈の発展を阻
害していると考えられる。読み手の時間という資源を効率的に投入するためにも、エタる現象の解明に取り組むべき
ではないだろうか。
なお、ここで断っておくと、本記事の目的はエター作家を非難することではない。
多くの作家は悪意から更新停止に陥るわけではないし、エタることは邪悪な行為(or不作為)ではない。
ほぼ全てのネット小説作家は自由意思に基づき無償で小説を公開しているだけであり、契約関係はないので、
読者が作者の行動を指示したり制限したりする法的・道義的権利はない。
例え途中でエタったとしても無償で娯楽を提供して貰えるのはとてもありがたいことである。
本記事の目的はエタる作家と更新を続けて完結させる作家の違いがどこから生じているかを解明し、小説がエタ
る確率を予測することにある。データが収集しやすいので、「小説家になろう」の作家を対象にする。
エターナる個別具体的な理由を知りたい読者はページのタイトルで検索して欲しい。
本記事の役割は、エター作家とそうでない作家(あるいは小説)は異なる性質・特徴を持つとの仮定の下、
なろう作家一般の性質を定量的に理解し、予測に役立てることである。
言うまでもなく、このアプローチには問題がある。エタるかそうでないかの違
いは観察できない作家の心理状況に強く依存すると考えられるので、ネット上に公開さ
れている情報だけでは不完全な解明・予測しかできないと予想されることである。しかしながら
、筆者の知る限り、部分的にであれ作家の更新停止という現象を実証的に解明した文献はない。
より精度の高いエタ予測を行うため、シンプルなモデルとデータから更新停止を分析してみる。
また、以下の通り「エターナる」を簡単に定義しておく。
○定義:
小説がエターナる:未完の連載小説が1年以上の更新停止に陥ること
→エタ作家:最後の更新した未完の連載小説の更新日時が1年以上前である作家
小説が生存(非エターナる):未完の連載小説が完結する。あるいは最後の更新が一年以内であること
エターナるとそうでない閾値を「1年以上」とした理論的根拠はなく、強いていうなら運営側の経験知の
活用である。なろうでは最後の更新から1年以上経過すると
小説目次ページの上部に「今後、次話投稿されない可能性が極めて高いです」
(半年以上だと「可能性が高い」との表現にとどまる)と表示されるようになる。
分析枠組み
全なろう作家からランダムにサンプルを抽出し、各種情報を収集、データを分析する。
「なろう」において小説を公開するにはアカウントを作
成する必要があり、作成した順に応じてユーザーにはそれぞれユーザーページの1から順に番号が割
り振られる。これを母集団のリストとみなし、無作為抽出を行った。小説ではなく作家がエタると
考え、作家とその「代表作」を観察単位とした。便宜的ではあるが、データ収集
時点で最後に更新されていた未完の連載小説を代表作と定義した。
データは2013年12月23日(24時ごろ)に収集した。当時存在したアカウントのう
ち(無作為に5000人抽出)、連載小説を有する作家は720人であった。
(ちなみに最小のユーザIDは25で最大は399729だった)
さらに2017年3月13日にこの720人を追跡調査し、
代表作の小説の更新状況を確認した。2013年のデータ収集時点で47%(339人)の小説がエタっており、エタ率は
3年後には85%に増加した。ついでいうと、88%が作家として活動停止に陥っているため、別の小説を連載しているわけでない。
以下に主なデータの概要を示した。
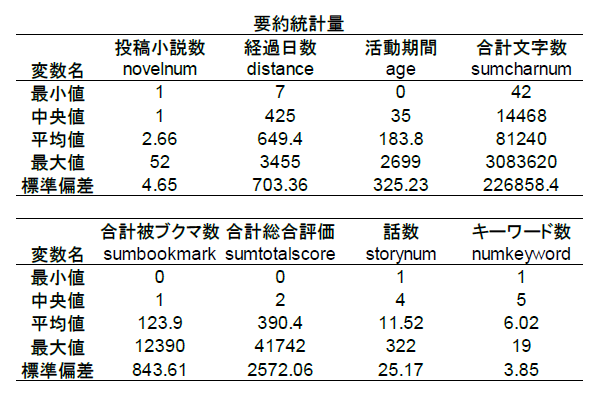
投稿小説数は720人の作家がそれぞれ投稿している小説の数である。平均が2.66作品で、最も
多い作家は52もの作品を投稿している。経過日数は最新の小説更新日時と2013年12月31日との日数の差である。
最大値が3455日なので、最古の最終更新は2013年末の約10年前ということを示している。活動期間は
作家としての活動期間の長さ(日)であり、最古の小説投稿日時と最新の小説更新日時の差である。
合計文字数はその作家の全ての小説の文字数を足し合わせたものであり、合計被ブクマ数も合計総合評価も同様である。
話数とキーワード数は代表作の数値を示している。
2013年末でエタっていた連載小説のうち、その後当該小説(=最後に更新していた連載作)で更新さ
れた割合は1.4%であった。1年以上の更新停止から連載を再開し更新を継続して2017年3月13日ま
で生存している小説は339分の1という低さだ。
2013年末でエタらず連載中だった小説のその後の動向を見てみると、
87%が現在までに1年以上の更新停止に至った。完結に至ったのはわずか7%で、データ収集後に更新したのは
そもそも30%に過ぎなかった。
何を予測するかを正しく選ぶことは、しばしば予測が正しいことより重要である。
言い換えると、我々はある作家のある小説が将来エタるかどうかを知りたいのか(eternal2017)、
作家としての執筆活動が続く見込みを知りたいのか(alive2017)、あるいは小説が完結するか
を知りたいのか(isnovelend)はっきりさせる必要がある。
差し当たり、ここではある作家のある小説が将来エタるかどうか(eternal2017)を予測することにする。
従って、以下で示す棒グラフ以外は全て小説のエタ予測である。
0ならば生存、1ならばエターというようにデータはコーディングされている。
このように予測対象(目的変数)は0か1をとる横断時データなので、
ロジットで分析した。
データから1つのサンプルを抜き出し、残りで除外したサンプルを予測するという方法で
エターの予測確率を計算した(一個抜き交差検証)。予測確率が50%を超える場合にエタると判別する
ことになる。
分析結果
予測性能評価
以下の棒グラフで示したのが予測パフォーマンスである。
結果の頑健性を調べるため、小説が将来エタるかどうか(黒っぽい棒)、という予測対象以外にも、2013年末の
データ収集以降に小説が更新されたか(「小説が更新なし」)、2017年3月時点で作家が執筆活動を続けているか
(「作家が活動停止」)、を予測対象として分析した。
一番上のグラフが全体の正答率(Accuracy)を、下2つのグラフが予測精度(Precision)を示している。
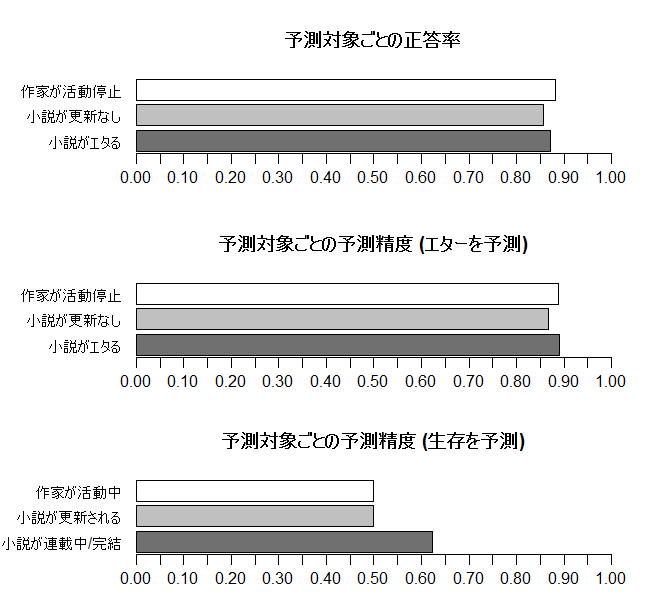
正答率とは、予測(エターか生存か/0か1か)が実際の状態と一致した割合である。予測精度とは、
1と予測した場合に実際の状態が1だった割合である。80%~90%と比較的数字の高い上2つのグラフは
エターを予測している。つまり、将来エタっているだろうと予測された小説のうち、実際にエターナるな小説な割合である。
一番下の棒グラフはエターでなく生存(小説がエタらず連載中or完結)を予測した場合の予測精度である。
一番下の棒グラフは0.62ほどなので、エタらないと予測した小説のうち62%が実際にエタらないということがわかる。
3年後の小説生存率は20%未満なので、生存の予測は難しい問題である。
変数の選択は小説のエター予測を基準としているので、小説の更新や作家の生存を予測したモデルでは低めのパフォー
マンスとなっている。
9割近い正答率・予測精度と聞けば、なかなか良さそうに思えるが、ここで8割以上の小説が2017年にはエタっていた
ことを思い出して欲しい。もし何も見ずに「全てエターナる」と予測すれば8割以上予測が当たるということである。
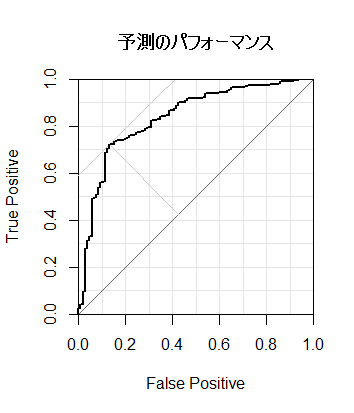
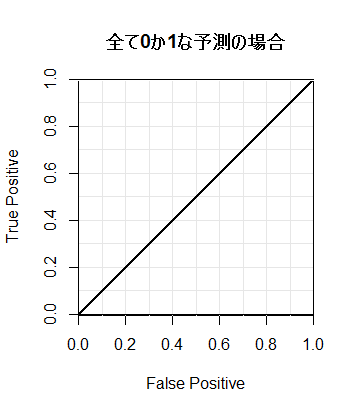
そこで、予測モデルがサイコロよりマシかどうかを確認するために以下の図を作成した。
この図の太めの黒線はROC(受信者操作特性)曲線を描画したもので、予測のパフォーマンスが視覚的に分かる。
黒い曲線が左上にあればあるほどパフォーマンスが高い。
もし全て0か1と予測した場合には曲線は図中の斜め45度の対角線と一致する。
サイコロなど乱数で適当に予測した場合、ROC曲線は対角線付近をうろつく。
100%の予測を行えた場合には、ROC曲線は左辺と上辺に張り付く形状となる。全ての予測をはずした場合はその逆である。
示したROC曲線は対角線の左上にあるので、予測モデルはそこそこ優れた予測を行えていることを示している。
(ROC曲線の詳細についてはこのサイトなどを参照。)
考察
予測モデルが役に立ちそうだということがわかった。しかし多くの読者が必要としているだろう
情報は、どの変数の組み合わせで精度が何%という話ではない。なので以下でモデルのパラメータを見ることで
実際に役立つ示唆を導き出してみる。例えば、「低評価の小説はエタりやすいのか? もしそうだとすればどれくらいか?」
という問いに答える。
以下の表がモデルのパラメータの推定結果である。小説の生存を予測している。読み飛ばしても問題ない。
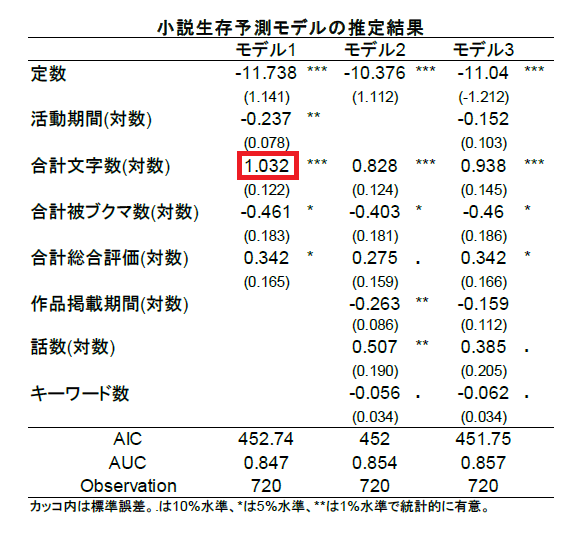
雑に言うとパラメータの値が正か負か、と*が付いているか(有意)を見ればよい。
モデル2とモデル3は(今までベースとしてきた)モデル1に変数を追加した場合どの程度結果が
変わるかを知りたい読者のために掲載しておいた。基本的に生存確率に影響を持つ変数のみ掲載している。
なので、キーワードに「異世界」か「ファンタジー」を含むかどうかは無関係だった。
例えば合計文字数のパラメータは***が付いているので、生存確率に影響を及ぼしている。
また値が1.032と正なので、合計文字数が多いほど、エタらず生存する可能性が高いことを
示している。絶対値で(定数を除いて)最大なので、どれだけ評価を受けているかよりも
小説に投じた労力が大きいほど、エタらすのに抵抗が生じるということになる。
(※)
合計被ブクマ数は*があり、-0.461と負の値なので、
合計被ブクマ数が多いほど、生存確率が低いことを示している。一方で合計総合評価
のパラメータの値は正なので、興味深い現象である。
総合評価はストーリー評価と文章評価とブクマ数×2で計算されるので、この結果を素直に解釈するなら、
作家はブクマで意欲を失い、ポイント評価でやる気を出すことになるが、かなり疑わしい。
しかしながらモデルが予測の役に立つことは確かなので、とりあえずはこの結果を
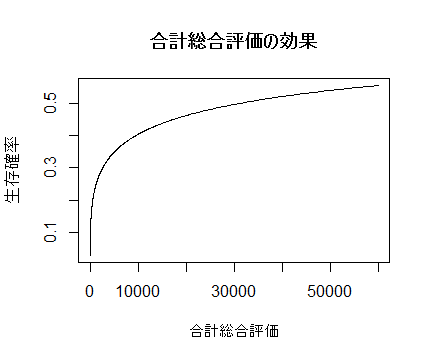
信用したとして、具体的な影響の幅を見てみよう。以下の図は合計文字数と
合計総合評価が増えた場合に生存確率がどれくらい変化するかを示したものである。
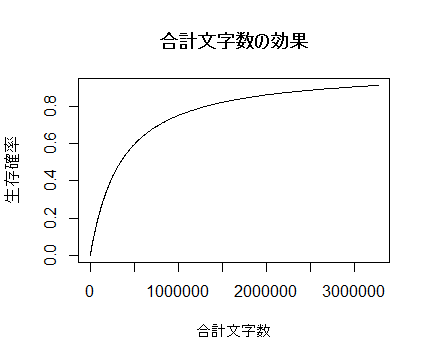 
左の図から(他の変数が平均値の時、)合計文字数が100万字あたりにかけて大きく生存
確率が上昇しているのが見て取れる。自然対数でいうと10から14の間である。
特に16万字から44万字付近の上がり幅が最も大きく、3年後の生存確率は31.5%から56.4%
にまで上昇している。小説の文字数が133万を超えると80%以上が生存している。また、
生存率50%の境界となる文字数は348014字であった。
右の図で示した(他の変数が平均値の時の)合計総合評価の効果は、合計文字数より急なカーブを描いている。
すなわち、総合評価が低い状態の時は1ptが作家に大きくやる気を与えるが、5万以上のptを
得ている作家は1000程度ポイントが増えたり減ったりしても気にしないということである。
0ptから6.4ptへの増加で生存率は2.6%上昇する。0ptから54ptなら7.4%の生存率上昇が
推定される一方、8103ptからの同じ7.4%の生存率上昇には追加の総合評価が11629pt必要である。
もし続きが気になる小説があるのなら、手間を惜しまずポイント評価を行うべきである。
その効果は小説の評価が低ければ低いほど(≒知名度が低いほど)大きい。当たり前の結果であるが、
その効果を定量的に把握できたのは成果である。
今後の課題
今回の分析の課題は数多くあるが、最大ものは分析デザインである。
まず、観察単位に混乱があった。作家を分析したいのか、小説を分析したいのか、
中途半端になっており結果の考察をしにくい一因となっている。
次に、不完全なデータであること。もっとサンプルサイズは大きくて良いし、変数も多くて良い。
例えば、ある小説がその作家唯一の小説なのか、完結後の2作目なのか、
同時連載中の1つなのか、などによって別の性質を持つ可能性があるが区別できていない。
また、PVや更新間隔など結果に影響していそうな変数が欠落している。
これら以外にも未知の変数によってパラメータの推定値が
間違っている可能性が排除できない(欠落変数バイアス)。
これらの課題の1つの解決策はパネルデータの整備である。つまり、複数の小説を
1月置きに観測することで横断面と時間方向での広がりを持つデータを収集することだ。
パネルデータの利点として、(時間を通じて一定な)観測できない異質性を考慮できたり、状態依存の程度も測定できる。
これらは総合評価の推定にも有益である。ある作者が高い評価を得ているのは、たまたまランクに乗ったからなのか、
あるいは文章が優れているからなのかを把握できる。また総合評価やブクマの減少が持つ効果も捉らえることができる。
もう1つの選択肢は実験である。具体的には、なるべく均質な小説群の一方にブクマをつけ、
そうでない小説群との間で生存率にどの程度の差が生まれるかを観察する、といった手法である。
最後の課題として、理論の不在が指摘できる。「何故エタるのか」という問いは、
本質的には「何故書くのか(書き続けるのか)」という問いと同義であろう。
書く理由を失ったから更新停止に至るのであり、この問いの考察には作家の執筆行動をモデル化する必要があるように感じる。
nコードを入力したら生存確率を出してくれるサービスを実現できたら理想である。
結論
本記事では、2013年末のなろうで作家と小説のデータを収集し分析した。
その結果、2013年末の時点で47%の小説がエタっており、そのエタ率は3年後には85%に増加したことがわかった。
また3年後のエターをロジットモデルで予測したところ、85%以上の正答率を達成した。
3年後の小説生存率(エタらず連載中あるいは完結)を62%の精度で予測可能であることがわかった。
文字数が多いほうが、総合評価が高いほうが生存率が高いという結果が示された一方
(文字数と総合評価の生存確率に与える効果を定量的に示した)、
小説がブックマークされている数が多いとエタる傾向があるかもしれないとわかった。
今回のような小さなサンプル・不十分な情報(小説の中身を考慮しない)の予測であっても
そこそこのパファーマンスを達成可能であることを示せたのはエター予測の試金石となるであろう。
ブクマの効果については更なる研究が必要である。
・雑なモデルでも62%の精度で小説の生存予測が可能
・続きが読みたい小説にはブクマよりポイント評価を優先した方が良いかもしれない
・エタるか知りたいなら文字数を見るべし
データ
csvデータと変数の説明書を公開しておく。
文字コードはたぶんUTF-8。
ROC曲線の描画は奥村先生の関数を利用した。
参考
[1] 佐々木尽左 (2016)
「『小説家になろう』をデータ分析してみた」/n5316df
[2] 佐々木尽左 (2017)
「『小説家になろう』をデータ分析してみた 2017年版」/n5628dw
[3] nis (2016)「最近の読者に人気のキーワードは
どれなの? ~主人公最強、悪役令嬢、勘違い~」/n6604dn
[4] 浦川隆寛, 伊東栄典 (2013)
「オンライン小説におけるキーワードの時系列傾向分析」、情報処理学会研究報告:B-3。
[5] 清水一憲, 伊東栄典, 廣川佐千男 (2013)
「集合知に基づくオンライン小説のランキング手法の提案と評価」、情報処理学会研究報告:B-3。
[6] フラン (2013)
「「小説家になろう」の三大人気要素と書籍化作品の傾向」、フラン☆Skin はてな支店。
※1 話数を変数として投入したモデル2とモデル3では、解釈が変わるので注意。"他の変数が一定"の時、合計文字数は1話当たりの平均文字数と同じになる。
|